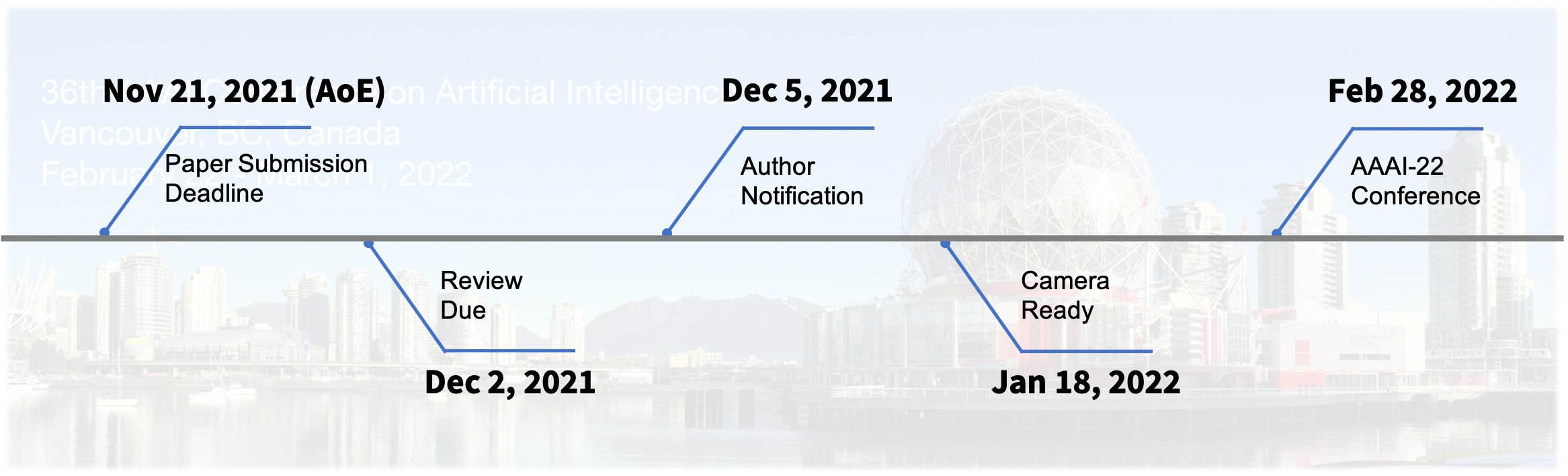
Important Dates
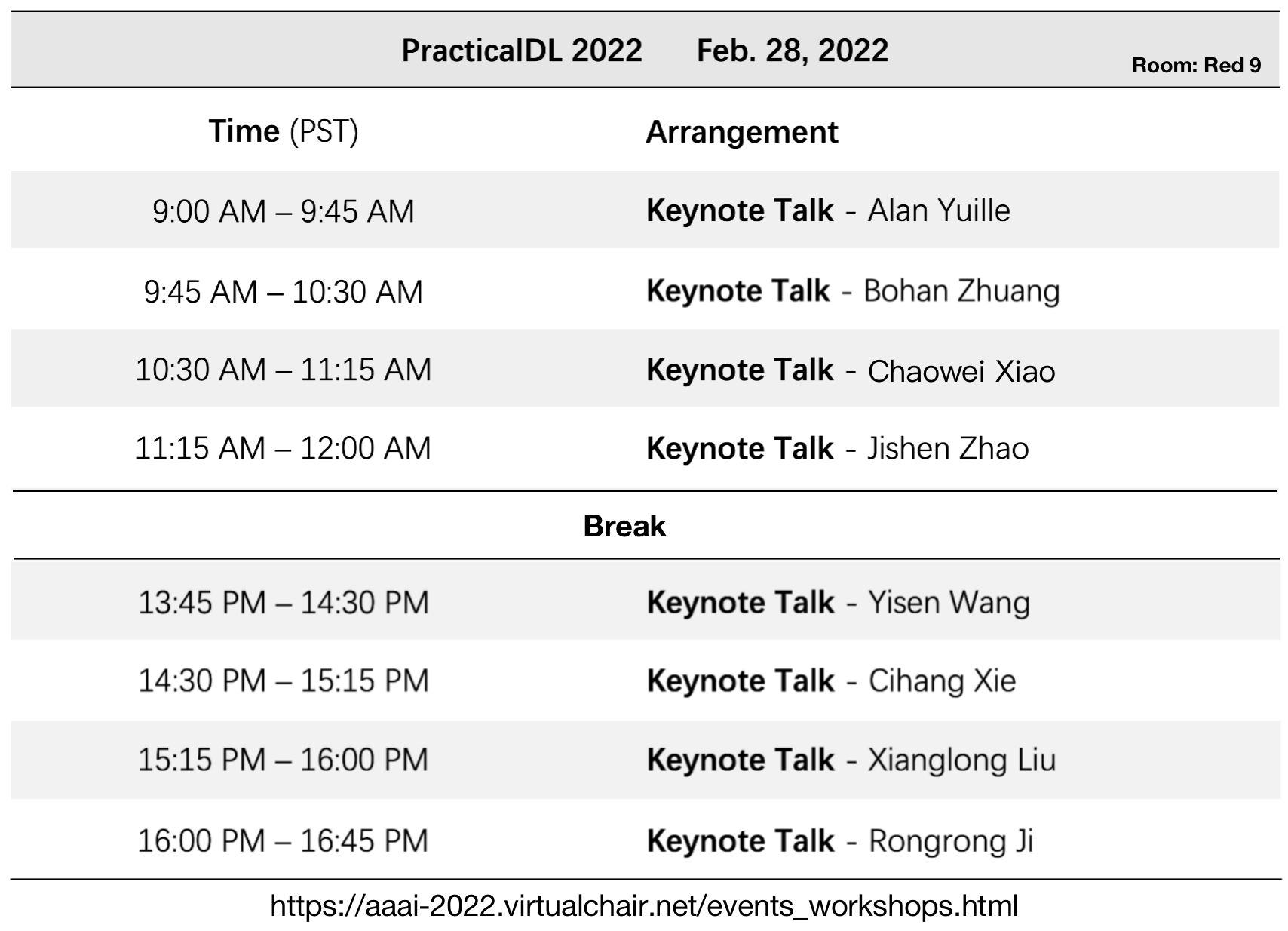
 |
Alan Yuille |
|
 |
Chaowei Xiao |
|
 |
Rongrong Ji |
|
 |
Xianglong Liu |
|
 |
Hao Su |
|
 |
Jishen Zhao |
UC San Diego |
 |
Tom Goldstein |
University of Maryland |
 |
Cihang Xie |
UC Santa Cruz |
 |
Yisen Wang |
Peking University |
 |
Bohan Zhuang |
Monash University Clayton Campus |
 |
Haotong Qin |
Beihang University |
 |
Yingwei Li |
Johns Hopkins University |
 |
Ruihao Gong |
SenseTime Research |
 |
Xinyun Chen |
UC Berkeley |
 |
Aishan Liu |
Beihang University |
 |
Xin Dong |
Harvard University |