Workshop Schedule
| Room: Ballroom FG |
 |
Aaron Gilad Kusne |
|
 |
Yawei Li |
|
 |
Jie Zhang |
|
 |
Haidong Kang |
|
 |
Xingyu Zheng |
|
 |
Haotong Qin |
|
 |
Aishan Liu |
|
|
Jie Zhang |
|
 |
Jiakai Wang |
|
 |
Yulun Zhang |
|
 |
Olivera Kotevska |
|
 |
Xianglong Liu |
|
 |
Michele Magno |
|
 |
Dacheng Tao |
|
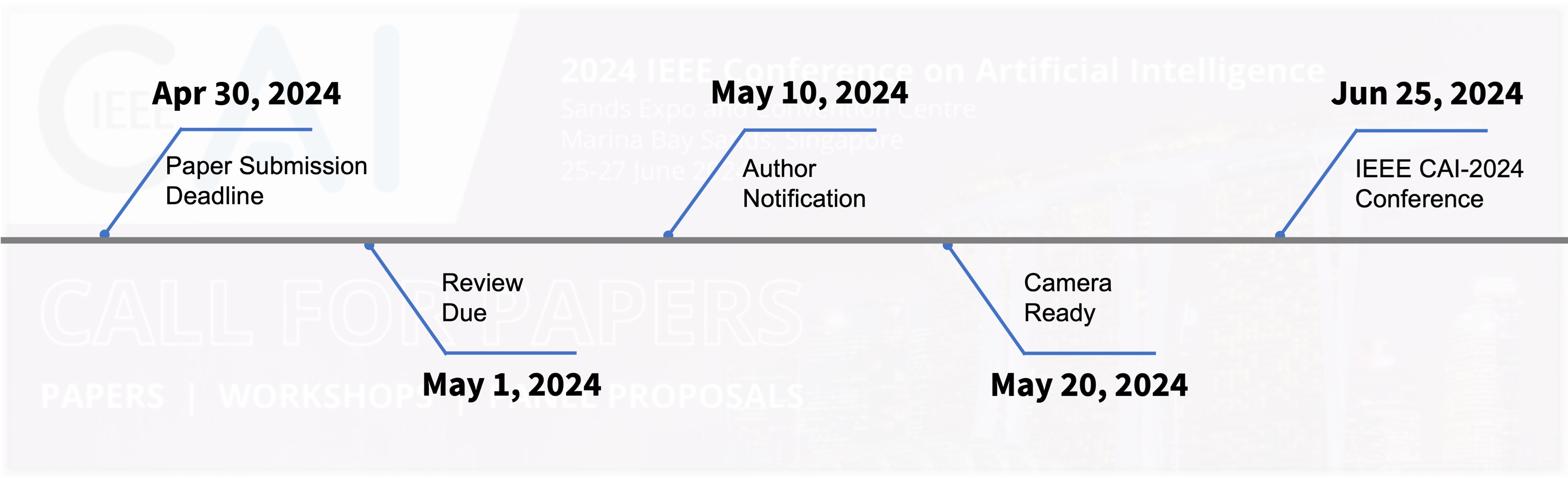
Best Paper Award: Dialectical Chain Distillation: Transferring Dialectical Reasoning from Teacher–Student Interactions to Small Language Models
Outstanding Paper Award: Leveraging LLM-based Sentiment Analysis for Portfolio Optimization with Proximal Policy Optimization



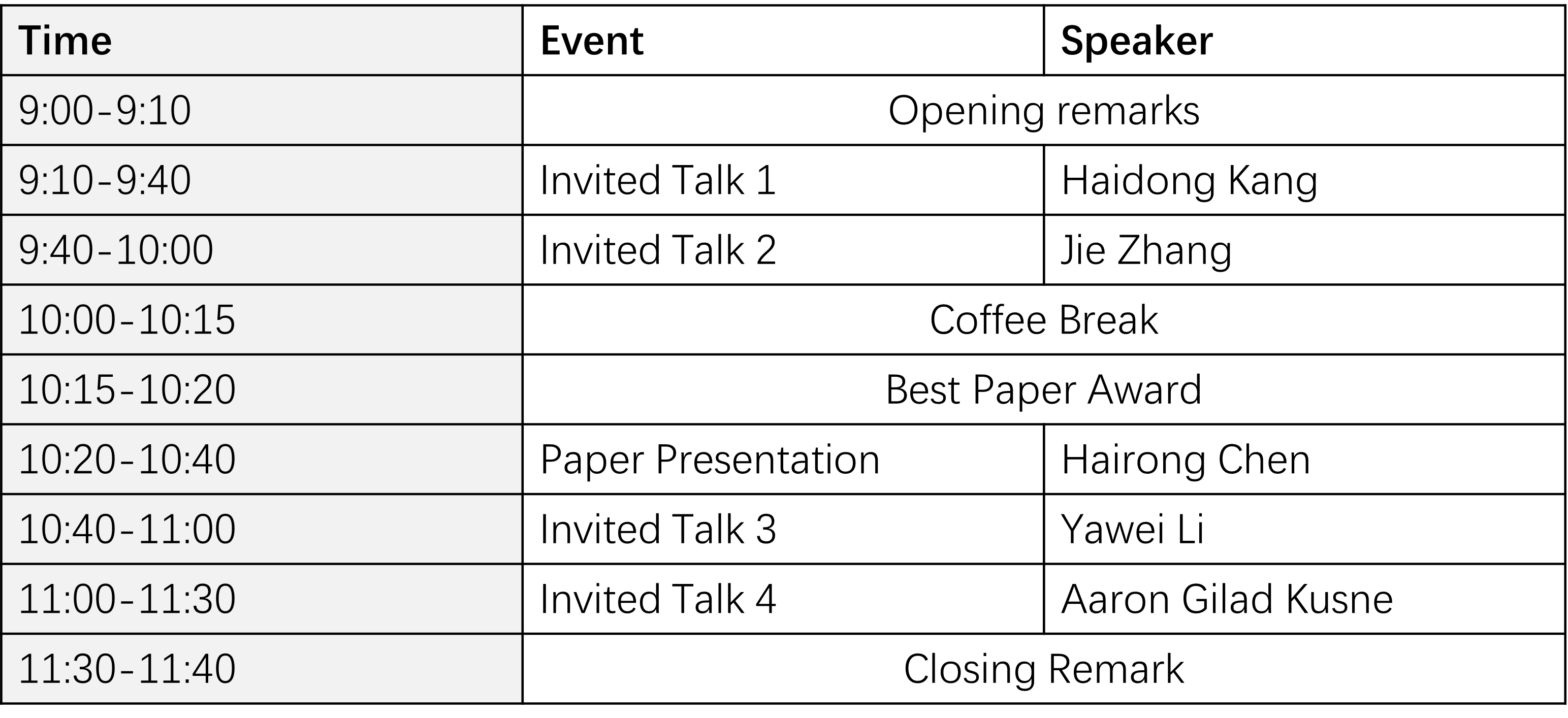
Opening

Speaker: Haidong Kang

Best Paper Award

Organizers
 |
Kewei Liao |
|
 |
Shenghao Jin |
|
 |
Xudong Ma |
|
 |
Wei Huang |
|
 |
Mingyuan Zhang |
|
 |
Zixiang Zhao |
|
 |
Renshuai Tao |
|
3rd Workshop on Practical Deep Learning: Towards Efficient and Reliable LLMs @ IEEE CAI 2024
2nd International Workshop on Practical Deep Learning in the Wild @ AAAI 2023
1st International Workshop on Practical Deep Learning in the Wild @ AAAI 2022